更新時間:2018-07-25 來源:黑馬程序員 瀏覽量:
一、MySQL 與其他數據庫的簡單比較
1.1性能比較
性能方面,一直是MySQL 引以為自豪的一個特點。在權威的第三方評測機構多次測試較量各種數據庫TPCC 值的過程中,MySQL 一直都有非常優異的表現,而且在其他所有商用的通用數據庫管理系統中,僅僅只有Oracle 數據庫能夠與其一較高下。至于各種數據庫詳細的性能數據,我這里就不便記錄,大家完全可以通過網上第三方評測機構公布的數據了解具體細節信息。
MySQL 一直以來奉行一個原則,那就是在保證足夠的穩定性的前提下,盡可能的提高自身的處理能力。也就是說,在性能和功能方面,MySQL 第一考慮的要素主要還是性能,MySQL希望自己是一個在滿足客戶99%的功能需求的前提下,花掉剩下的大部分精力來性能努力,而不是希望自己是成為一個比其他任何數據庫的功能都要強大的數據庫產品。
1.2可靠性
關于可靠性的比較,并沒有太多詳細的評測比較數據,但是從目前業界的交流中可以了解到,幾大商業廠商的數據庫的可靠性肯定是沒有太多值得懷疑的。但是做為開源數據庫管理系統的代表,MySQL 也有非常優異的表現,而并不是像有些人心中所懷疑的那樣,因為不是商業廠商所提供,就會不夠穩定不夠健壯。從當前最火的Facebook 這樣大型的網站都是使用MySQL 數據庫,就可以看出,MySQL 在穩定可靠性方面,并不會比我們的商業廠商的產品有太多遜色。而且排在全球前10 位的大型網站里面,大部分都有部分業務是運行在MySQL數據庫環境上,如Yahoo,Google 等。
總的來說,MySQL 數據庫在發展過程中一直有自己的三個原則:簡單、高效、可靠。從上面的簡單比較中,我們也可以看出,在MySQL 自己的所有三個原則上面,沒有哪一項是做得不好的。而且,雖然功能并不是MySQL 自身所追求的三個原則之一,但是考慮到當前用戶量的急劇增長,用戶需求越來越越多樣化,MySQL 也不得不在功能方面做出大量的努力,來不斷滿足客戶的新需求。比如最近版本中出現的Eent Scheduler(類似于Oracle 的Job 功能),Partition 功能,自主研發的Maria 存儲引擎在功能方面的擴展,Falcon 存儲引擎對事務的支持等等,都證明了MySQL 在功能方面也開始了不懈的努力。
任何一種產品,都不可能是完美的,也不可能適用于所有用戶。我們只有衡量了每一種產品的各種特性之后,從中選擇出一種最適合于自身的產品。
二、MySQL 的主要適用場景
據說目前MySQL 用戶已經達千萬級別了,其中不乏企業級用戶。可以說是目前最為流行的開源數據庫管理系統軟件了。任何產品都不可能是萬能的,也不可能適用于所有的應用場景。
那么MySQL 到底在什么場景下適用什么場景下不適用呢?
1、Web 網站系統
Web 站點,是MySQL 最大的客戶群,也是MySQL 發展史上最為重要的支撐力量,這一點在最開始的MySQL Server 簡介部分就已經說明過。
MySQL 之所以能成為Web 站點開發者們最青睞的數據庫管理系統,是因為MySQL 數據庫的安裝配置都非常簡單,使用過程中的維護也不像很多大型商業數據庫管理系統那么復雜,而且性能出色。還有一個非常重要的原因就是MySQL 是開放源代碼的,完全可以免費使用。
2、日志記錄系統
MySQL 數據庫的插入和查詢性能都非常的高效,如果設計地較好,在使用MyISAM 存儲引擎的時候,兩者可以做到互不鎖定,達到很高的并發性能。所以,對需要大量的插入和查詢日志記錄的系統來說,MySQL 是非常不錯的選擇。比如處理用戶的登錄日志,操作日志等,都是非常適合的應用場景。
3、數據倉庫系統
隨著現在數據倉庫數據量的飛速增長,我們需要的存儲空間越來越大。數據量的不斷增長,使數據的統計分析變得越來越低效,也越來越困難。怎么辦?這里有幾個主要的解決思路,一個是采用昂貴的高性能主機以提高計算性能,用高端存儲設備提高I/O 性能,效果理想,但是成本非常高;第二個就是通過將數據復制到多臺使用大容量硬盤的廉價pc server上,以提高整體計算性能和I/O 能力,效果尚可,存儲空間有一定限制,成本低廉;第三個,通過將數據水平拆分,使用多臺廉價的pc server 和本地磁盤來存放數據,每臺機器上面都只有所有數據的一部分,解決了數據量的問題,所有pc server 一起并行計算,也解決了計算能力問題,通過中間代理程序調配各臺機器的運算任務,既可以解決計算性能問題又可以解決I/O 性能問題,成本也很低廉。在上面的三個方案中,第二和第三個的實現,MySQL 都有較大的優勢。通過MySQL 的簡單復制功能,可以很好的將數據從一臺主機復制到另外一臺,不僅僅在局域網內可以復制,在廣域網同樣可以。當然,很多人可能會說,其他的數據庫同樣也可以做到,不是只有MySQL 有這樣的功能。確實,很多數據庫同樣能做到,但是MySQL是免費的,其他數據庫大多都是按照主機數量或者cpu 數量來收費,當我們使用大量的pcserver 的時候,license 費用相當驚人。第一個方案,基本上所有數據庫系統都能夠實現,但是其高昂的成本并不是每一個公司都能夠承擔的。
4、嵌入式系統
嵌入式環境對軟件系統最大的限制是硬件資源非常有限,在嵌入式環境下運行的軟件系統,必須是輕量級低消耗的軟件。MySQL 在資源的使用方面的伸縮性非常大,可以在資源非常充裕的環境下運行,也可以在資源非常少的環境下正常運行。它對于嵌入式環境來說,是一種非常合適的數據庫系統,而且MySQL 有專門針對于嵌入式環境的版本。
三、Query 語句對系統性能的影響
我想對于各位來說,肯定都清楚SQL 語句的優劣是對性能有影響的,但是到底有多大影響可能每個人都會有不同的體會,每個SQL 語句在優化之前和優化之后的性能差異也是各不相同,所以對于性能差異到底有多大這個問題我們我們這里就不做詳細分析了。我們重點分析實現同樣功能的不同SQL 語句在性能方面會產生較大的差異的根本原因,并通過一個較為典型的示例來對我們的分析做出相應的驗證。
為什么返回完全相同結果集的不同SQL 語句,在執行性能方面存在差異呢?這里我們先從SQL 語句在數據庫中執行并獲取所需數據這個過程來做一個大概的分析了。
當MySQL Server 的連接線程接收到Client 端發送過來的SQL 請求之后,會經過一系列的分解Parse,進行相應的分析。然后,MySQL 會通過查詢優化器模塊(Optimizer)根據該SQL 所設涉及到的數據表的相關統計信息進行計算分析,然后再得出一個MySQL 認為最合理最優化的數據訪問方式,也就是我們常說的“執行計劃”,然后再根據所得到的執行計劃通過調用存儲引擎借口來獲取相應數據。然后再將存儲引擎返回的數據進行相關處理,并以Client 端所要求的格式作為結果集返回給Client 端的應用程序。
注:這里所說的統計數據,是我們通過ANALYZE TABLE 命令通知MySQL 對表的相關數據做分析之后所獲得到的一些數據統計量。這些統計數據對MySQL 優化器而言是非常重要的,優化器所生成的執行計劃的好壞,主要就是由這些統計數據所決定的。實際上,在其他一些數據庫管理軟件中也有類似相應的統計數據。
我們都知道,在數據庫管理軟件中,最大的性能瓶頸就是在于磁盤IO,也就是數據的存取操作上面。而對于同一份數據,當我們以不同方式去尋找其中的某一點內容的時候,所需要讀取的數據量可能會有天壤之別,所消耗的資源也自然是區別甚大。所以,當我們需要從數據庫中查詢某個數據的時候,所消耗資源的多少主要就取決于數據庫以一個什么樣的數據讀取方式來完成我們的查詢請求,也就是取決于SQL 語句的執行計劃。
對于唯一一個SQL 語句來說,經過MySQL Parse 之后分解的結構都是固定的,只要統計信息穩定,其執行計劃基本上都是比較固定的。而不同寫法的SQL 語句,經過MySQL Parse 之后分解的結構結構就可能完全不同,即使優化器使用完全一樣的統計信息來進行優化,最后所得出的執行計劃也可能完全不一樣。而執行計劃又是決定一個SQL 語句最終的資源消耗量的主要因素。所以,實現功能完全一樣的SQL 語句,在性能上面可能會有差別巨大的性能消耗。當然,如果功能一樣,而且經過MySQL 的優化器優化之后的執行計劃也完全一致的不同SQL 語句在資源消耗方面可能就相差很小了。當然這里所指的消耗主要是IO 資源的消耗,并不包括CPU 的消耗。
下面我們將通過一兩個具體的示例來分析寫法不一樣而功能完全相同的兩條SQL 的在性能方面的差異。
示例一
需求:取出某個group(假設id 為100)下的用戶編號(id),用戶昵稱(nick_name)、用戶性別( sexuality ) 、用戶簽名( sign ) 和用戶生日( birthday ) , 并按照加入組的時間(user_group.gmt_create)來進行倒序排列,取出前20 個。
解決方案一、
解決方案二、
我們先來看看執行計劃: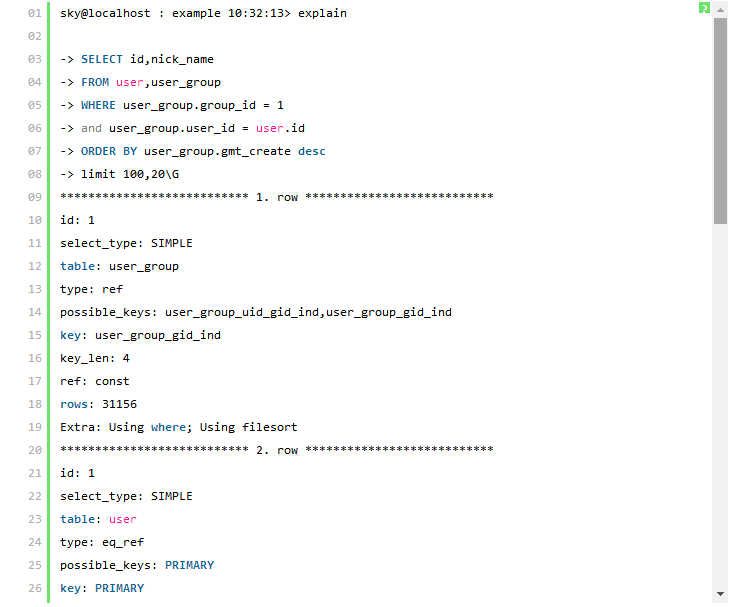
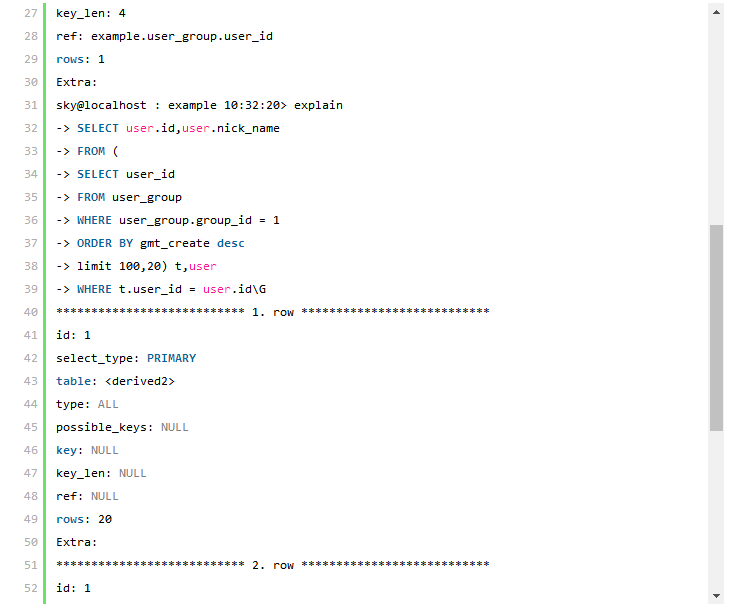
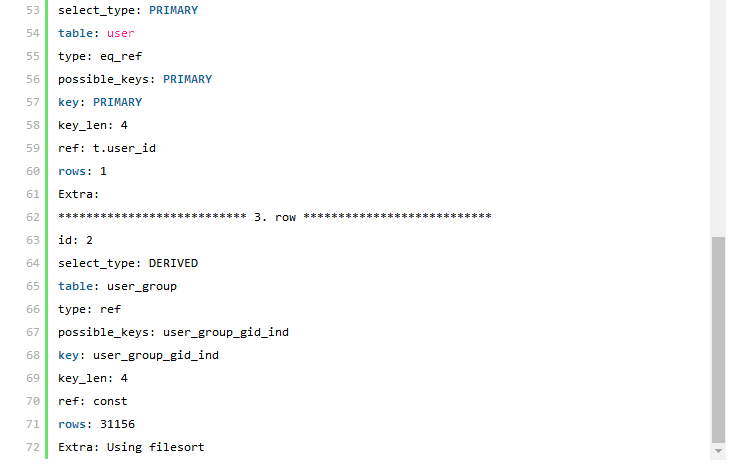
執行計劃對比分析:
解決方案一中的執行計劃顯示MySQL 在對兩個參與Join 的表都利用到了索引,user_group 表利用了user_group_gid_ind 索引( key: user_group_gid_ind ) , user 表利用到了主鍵索引( key:PRIMARY),在參與Join 前MySQL 通過Where 過濾后的結果集與user 表進行Join,最后通過排序取出Join 后結果的“limit 100,20”條結果返回。
解決方案二的SQL 語句利用到了子查詢,所以執行計劃會稍微復雜一些,首先可以看到兩個表都和解決方案1 一樣都利用到了索引(所使用的索引也完全一樣),執行計劃顯示該子查詢以user_group 為驅動,也就是先通過user_group 進行過濾并馬上進行這一論的結果集排序,也就取得了SQL 中的“limit 100,20”條結果,然后與user 表進行Join,得到相應的數據。這里可能有人會懷疑在自查詢中從user_group表所取得與user 表參與Join的記錄條數并不是20 條,而是整個group_id=1 的所有結果。那么清大家看看該執行計劃中的第一行,該行內容就充分說明了在外層查詢中的所有的20 條記錄全部被返回。 通過比較兩個解決方案的執行計劃,我們可以看到第一中解決方案中需要和user 表參與Join 的記錄數MySQL 通過統計數據估算出來是31156,也就是通過user_group 表返回的所有滿足group_id=1 的記錄數(系統中的實際數據是20000)。而第二種解決方案的執行計劃中,user 表參與Join 的數據就只有20條,兩者相差很大,通過本節最初的分析,我們認為第二中解決方案應該明顯優于第一種解決方案。
下面我們通過對比兩個解決覺方案的SQL 實際執行的profile 詳細信息,來驗證我們上面的判斷。由于SQL 語句執行所消耗的最大兩部分資源就是IO和CPU,所以這里為了節約篇幅,僅列出BLOCK IO 和CPU兩項profile 信息:先打開profiling 功能,然后分別執行兩個解決方案的SQL 語句:

查看系統中的profile 信息,剛剛執行的兩個SQL 語句的執行profile 信息已經記錄下來了:

 我們先看看兩條SQL 執行中的IO 消耗,兩者區別就在于“Sorting result”,我們回顧一下前面執行計劃的對比,兩個解決方案的排序過濾數據的時機不一樣,排序后需要取得的數據量一個是20000,一個是20,正好和這里的profile 信息吻合,第一種解決方案的“Sorting result”的IO 值是第二種解決方案的將近500 倍。然后再來看看CPU 消耗,所有消耗中,消耗最大的也是“Sorting result”這一項,第一個消耗多出的緣由和上面IO 消耗差異是一樣的。結論:通過上面兩條功能完全相同的SQL 語句的執行計劃分析,以及通過實際執行后的profile 數據的驗證,都證明了第二種解決方案優于第一種解決方案。同時通過后者的實際驗證,也再次證明了我們前面所做的執行計劃基本決定了SQL 語句性能。
我們先看看兩條SQL 執行中的IO 消耗,兩者區別就在于“Sorting result”,我們回顧一下前面執行計劃的對比,兩個解決方案的排序過濾數據的時機不一樣,排序后需要取得的數據量一個是20000,一個是20,正好和這里的profile 信息吻合,第一種解決方案的“Sorting result”的IO 值是第二種解決方案的將近500 倍。然后再來看看CPU 消耗,所有消耗中,消耗最大的也是“Sorting result”這一項,第一個消耗多出的緣由和上面IO 消耗差異是一樣的。結論:通過上面兩條功能完全相同的SQL 語句的執行計劃分析,以及通過實際執行后的profile 數據的驗證,都證明了第二種解決方案優于第一種解決方案。同時通過后者的實際驗證,也再次證明了我們前面所做的執行計劃基本決定了SQL 語句性能。
首發:黑馬程序員javaEE培訓學院
首發:http://java.itheima.com/
















 JavaEE
JavaEE 鴻蒙應用開發
鴻蒙應用開發 集成電路應用開發
集成電路應用開發 人工智能開發
人工智能開發 AI+Linux云計算運維
AI+Linux云計算運維 Python+大數據開發
Python+大數據開發 AI+設計
AI+設計 軟件測試
軟件測試 新媒體+短視頻
新媒體+短視頻 HTML&JS+前端
HTML&JS+前端
















.jpg)