更新時間:2020-05-29 來源:黑馬程序員 瀏覽量:
Spark Streaming是構建在Spark上的實時計算框架,且是對Spark Core API的一個擴展,它能夠實現對流數據進行實時處理,并具有很好的可擴展性、高吞吐量和容錯性。Spark Streaming具有如下顯著特點。
(1)易用性。
Spark Streaming支持Java、Python、Scala等編程語言,可以像編寫離線程序一樣編寫實時計算的程序求照的器。
(2)容錯性。
Spark Streaming在沒有額外代碼和配置的情況下,可以恢復丟失的數據。對于實時計算來說,容錯性至關重要。首先要明確一下Spak中RDD的容錯機制,即每一個RDD都是個不可變的分布式可重算的數據集,它記錄著確定性的操作繼承關系(lineage),所以只要輸入數據是可容錯的,那么任意一個RDD的分區(Partition)出錯或不可用,都可以使用原始輸入數據經過轉換操作重新計算得到。
(3)易整合性。
Spark Streaming可以在Spark上運行,并且還允許重復使用相同的代碼進行批處理。也就是說,實時處理可以與離線處理相結合,實現交互式的查詢操作。
Spark Streaming工作原理
Spark Streaming支持從多種數據源獲取數據,包括 Kafka、Flume、Twitter、LeroMQ、Kinesis以及TCP Sockets數據源。當Spark Streaming從數據源獲取數據之后,可以使用如map、 reduce、join和 window等高級函數進行復雜的計算處理,最后將處理的結果存儲到分布式文件系統、數據庫中,最終利用實時web儀表板進行展示。Spark Streaming支持的輸入、輸出源如下圖所示。
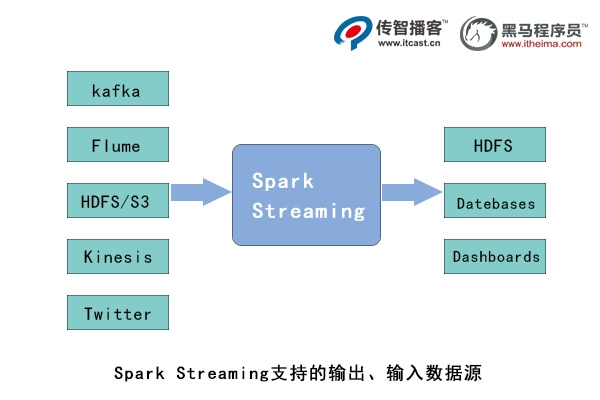
在上圖中,Spark Streaming先接收實時輸入的數據流,并且將數據按照一定的時間間隔分成一批批的數據,每一段數據都轉變成Spark中的RDD,接著交由Spark引擎進行處理,最后將處理結果數據輸出到外部儲存系統。

猜你喜歡:
















 JavaEE
JavaEE 鴻蒙應用開發
鴻蒙應用開發 集成電路應用開發
集成電路應用開發 人工智能開發
人工智能開發 AI+Linux云計算運維
AI+Linux云計算運維 Python+大數據開發
Python+大數據開發 AI+設計
AI+設計 軟件測試
軟件測試 新媒體+短視頻
新媒體+短視頻 HTML&JS+前端
HTML&JS+前端
















.jpg)