更新時間:2020-10-15 來源:黑馬程序員 瀏覽量:
HDFS,全稱Hadoop Distributed File System,意思是分布式文件系統。Hadoop分布式文件系統是指被設計成適合du運行在通用硬件(commodity hardware)上的分zhi布式文件系統。
HDFS 源于 Google 在2003年10月份發表的GFS(Google File System)論文,接下來,我們從傳統的文件系統入手,開始學習分布式文件系統,以及分布式文件系統是如何演變而來。
傳統的文件系統對海量數據的處理方式是將數據文件直接存儲在一臺服務器上,如圖1所示。
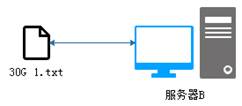
圖1 傳統文件系統
從圖1可以看出,傳統的文件系統在存儲數據時,會遇到兩個問題,具體如下:
l 當數據量越來越大時,會遇到存儲瓶頸,就需要擴容;
l 由于文件過大,上傳和下載都非常耗時;
為了解決傳統文件系統遇到的存儲瓶頸問題,那么首先考慮的就是擴容,擴容有兩種形式,一種是縱向擴容,即增加磁盤和內存;另一種是橫向擴容,即增加服務器數量。通過擴大規模從而達到分布式存儲,這種存儲形式就是分布式文件存儲的雛形,如圖2所示。

圖2 分布式文件系統雛形
解決了分布式文件系統的存儲瓶頸問題之后,那么還需要解決文件上傳與下載的效率問題,常規的解決辦法是將一個大的文件切分成多個數據塊,將數據塊以并行的方式進行存儲。這里以30G的文本文件為例,將其切分成3塊,每塊大小10G(實際上每個數據塊都很小只有100M左右),將其存儲在文件系統中,如圖3所示。

圖3 分布式文件系統雛形
從圖3可以看出,原先一臺服務器要存儲30G的文件,此時每臺服務器只需要存儲10G的數據塊就完成了工作,從而解決了上傳下載的效率問題。但是文件通過數據塊分別存儲在服務器集群中,那么如何獲取一個完整的文件呢?針對這個問題,就需要再考慮增加一臺服務器,專門用來記錄文件被切割后的數據塊信息以及數據塊的存儲位置信息,如圖4所示。
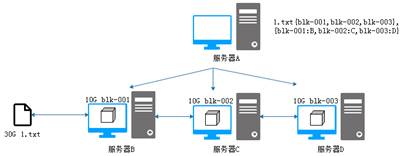
圖4 HDFS文件系統雛形
從圖4可以看出,文件存儲系統中增加了一臺服務器A用于管理其他服務器,服務器A記錄著文件被切分成多少個數據塊,這些數據塊分別存儲在哪臺服務器中,這樣當客戶端訪問服務器A請求下載數據文件時,就能夠通過類似查找目錄的方式查找數據了。
通過前面的操作,看似解決了所有問題,但其實還有一個非常關鍵的問題需要處理,那就是當存儲數據塊的服務器中突然有一臺機器宕機,我們就無法正常的獲取文件了,這個問題被稱為單點故障。針對這個問題,可以采用備份的機制進行解決,如圖5所示。
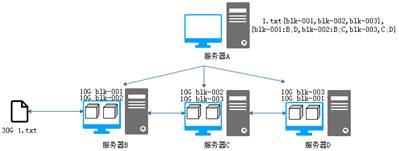
圖5 HDFS文件系統
從圖5可以看出,每個服務器中都存儲兩個數據塊,進行備份。服務器B存儲blk-001和blk-002,服務器C存儲blk-002和blk-003,服務器D存儲blk-001和blk-003。此時,當服務器C突然宕機,我們也可以通過服務器B和服務器D查詢完整的數據塊供客戶端訪問下載。此時就形成了簡單的HDFS分布式文件系統。
這里的服務器A被稱為NameNode,它維護著文件系統內所有文件和目錄的相關信息,服務器B、C、D被稱為DataNode,用于存儲數據塊。
















 JavaEE
JavaEE 鴻蒙應用開發
鴻蒙應用開發 集成電路應用開發
集成電路應用開發 人工智能開發
人工智能開發 AI+Linux云計算運維
AI+Linux云計算運維 Python+大數據開發
Python+大數據開發 AI+設計
AI+設計 軟件測試
軟件測試 新媒體+短視頻
新媒體+短視頻 HTML&JS+前端
HTML&JS+前端
















.jpg)