更新時間:2021-08-19 來源:黑馬程序員 瀏覽量:
在軟件開發中,為了提高軟件系統的可維護性和可復用性,增加軟件的可擴展性和靈活性,程序員要盡量根據6條原則來開發程序,從而提高軟件開發效率、節約軟件開發成本和維護成本。這六條分別是開閉原則、里氏代換原則、依賴倒轉原則、接口隔離原則、迪米特法則、合成復用原則,下面主要介紹里依賴倒轉原則。
高層模塊不應該依賴低層模塊,兩者都應該依賴其抽象;抽象不應該依賴細節,細節應該依賴抽象。簡單的說就是要求對抽象進行編程,不要對實現進行編程,這樣就降低了客戶與實現模塊間的耦合。
下面看一個例子來理解依賴倒轉原則
【例】組裝電腦
現要組裝一臺電腦,需要配件cpu,硬盤,內存條。只有這些配置都有了,計算機才能正常的運行。選擇cpu有很多選擇,如Intel,AMD等,硬盤可以選擇希捷,西數等,內存條可以選擇金士頓,海盜船等。
類圖如下:
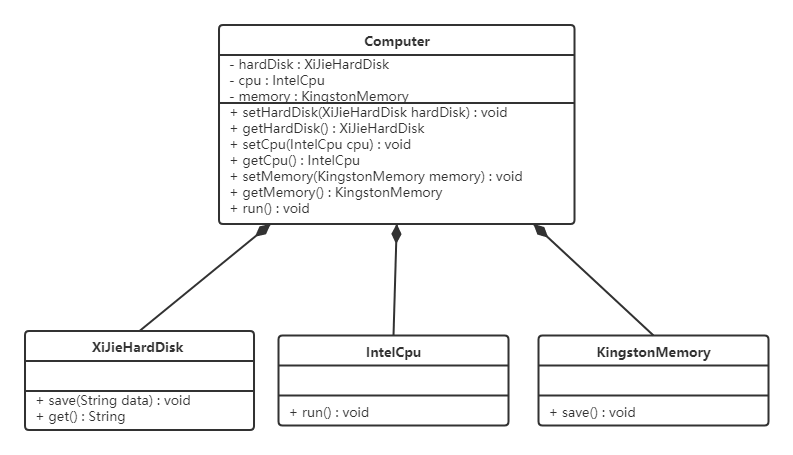
代碼如下:
希捷硬盤類(XiJieHardDisk):
public class XiJieHardDisk implements HardDisk {
public void save(String data) {
System.out.println("使用希捷硬盤存儲數據" + data);
}
public String get() {
System.out.println("使用希捷希捷硬盤取數據");
return "數據";
}
}
Intel處理器(IntelCpu):
public class IntelCpu implements Cpu { public void run() { System.out.println("使用Intel處理器"); } }金士頓內存條(KingstonMemory):
public class KingstonMemory implements Memory { public void save() { System.out.println("使用金士頓作為內存條"); } }電腦(Computer):
public class Computer {
private XiJieHardDisk hardDisk;
private IntelCpu cpu;
private KingstonMemory memory;
public IntelCpu getCpu() {
return cpu;
}
public void setCpu(IntelCpu cpu) {
this.cpu = cpu;
}
public KingstonMemory getMemory() {
return memory;
}
public void setMemory(KingstonMemory memory) {
this.memory = memory;
}
public XiJieHardDisk getHardDisk() {
return hardDisk;
}
public void setHardDisk(XiJieHardDisk hardDisk) {
this.hardDisk = hardDisk;
}
public void run() {
System.out.println("計算機工作");
cpu.run();
memory.save();
String data = hardDisk.get();
System.out.println("從硬盤中獲取的數據為:" + data);
}
}
測試類(TestComputer):
測試類用來組裝電腦。
public class TestComputer {
public static void main(String[] args) {
Computer computer = new Computer();
computer.setHardDisk(new XiJieHardDisk());
computer.setCpu(new IntelCpu());
computer.setMemory(new KingstonMemory());
computer.run();
}
}
上面代碼可以看到已經組裝了一臺電腦,但是似乎組裝的電腦的cpu只能是Intel的,內存條只能是金士頓的,硬盤只能是希捷的,這對用戶肯定是不友好的,用戶有了機箱肯定是想按照自己的喜好,選擇自己喜歡的配件。
根據依賴倒轉原則進行改進:
代碼我們只需要修改Computer類,讓Computer類依賴抽象(各個配件的接口),而不是依賴于各個組件具體的實現類。
類圖如下:
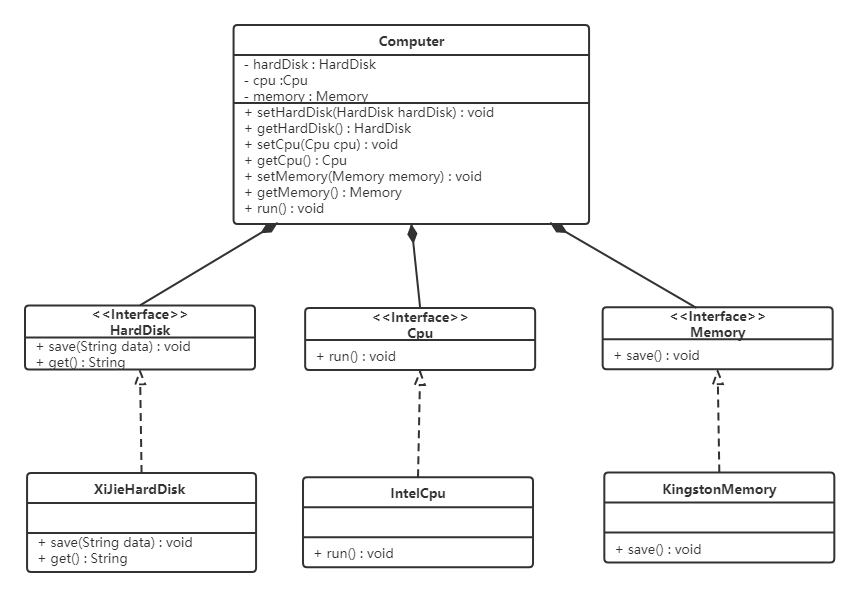
電腦(Computer):
public class Computer {
private HardDisk hardDisk;
private Cpu cpu;
private Memory memory;
public HardDisk getHardDisk() {
return hardDisk;
}
public void setHardDisk(HardDisk hardDisk) {
this.hardDisk = hardDisk;
}
public Cpu getCpu() {
return cpu;
}
public void setCpu(Cpu cpu) {
this.cpu = cpu;
}
public Memory getMemory() {
return memory;
}
public void setMemory(Memory memory) {
this.memory = memory;
}
public void run() {
System.out.println("計算機工作");
}
}
面向對象的開發很好的解決了這個問題,一般情況下抽象的變化概率很小,讓用戶程序依賴于抽象,實現的細節也依賴于抽象。即使實現細節不斷變動,只要抽象不變,客戶程序就不需要變化。這大大降低了客戶程序與實現細節的耦合度。
猜你喜歡:
















 JavaEE
JavaEE 鴻蒙應用開發
鴻蒙應用開發 集成電路應用開發
集成電路應用開發 人工智能開發
人工智能開發 AI+Linux云計算運維
AI+Linux云計算運維 Python+大數據開發
Python+大數據開發 AI+設計
AI+設計 軟件測試
軟件測試 新媒體+短視頻
新媒體+短視頻 HTML&JS+前端
HTML&JS+前端
















.jpg)