更新時間:2022-08-26 來源:黑馬程序員 瀏覽量:
背景
筆者以前在電商公司,我們需要在8月18號做大促活動,我們會提前一天給所有的用戶推送活動信息,且需要根據用戶畫像生成不同的推送內容。
當時我們總共有80萬用戶左右。
經測試,通過Spring Task和分布式鎖,單臺機器同時開啟5個線程,執行時間需要27個小時左右,即便開10個線程,需要14個小時左右,顯然執行時間過長。
解決方案
當時個推服務部署節點有3臺,在每年大促期間可動態擴容,其余的機器資源沒有充分利用起來。
要想短時間內完成推送,那么就得想辦法讓每臺機器各自分一部分用戶數據去執行,這樣效率可提高原來的N倍。
那么就需要分布式任務去執行,核心思想如下圖:
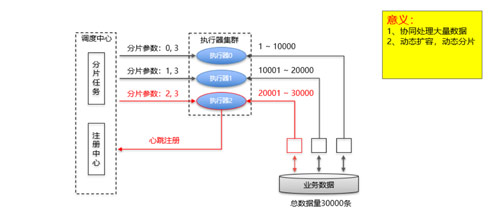
經過調研現有的開源的分布式任務調度框架,決定在elastic-job和xxl-job中選一個
[Elastic Job](https://github.com/elasticjob)是當當網開源一個分布式調度解決方案,由兩個相互獨立的子項目Elastic-Job-Lite和Elastic-Job-Cloud組成;定位為輕量級無中心化解決方案,使用 jar 包的形式提供分布式任務的協調服務。支持分布式調度協調、彈性擴容縮容、失效轉移、錯過執行作業重觸發、并行調度、自診斷和修復等等功能特性。
[XXL-Job官網](https://github.com/xuxueli/xxl-job)是大眾點評發布的分布式任務調度平臺,其核心設計目標是開發迅速、學習簡單、輕量級、易擴展。現已開放源代碼并接入多家公司線上產品線,開箱即用。
更傾向于選擇XXL-JOB:
1. 輕量級,支持通過Web頁面對任務進行動態CRUD操作,操作簡單
2. 只依賴數據庫作為集群注冊中心,接入開發簡單,不需要ZK
3. 高可用、解耦、高性能、監控報警、分片、重試、故障轉移
4. 團隊持續開發,社區活躍
5. 支持后臺直接查看每個任務執行實時日志
具體實現
在項目中集成xxl-job客戶端
<dependency> <groupId>com.xuxueli</groupId> <artifactId>xxl-job-core</artifactId> <version>2.2.0</version> </dependency>
在配置文件中配置xxl-job信息
xxl: job: accessToken: admin: addresses: http://xxl部署IP地址:8080/xxl-job-admin executor: appname: vm-service address: ip: port: 9989 logretentiondays: 30
新增XxlJobConfig.java
package com.itheima.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* xxl-job config
*
* @author xuxueli 2017-04-28
*/
@Configuration
@Slf4j
public class XxlJobConfig {
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
// @Value("${xxl.job.executor.logpath}")
// private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
log.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
//xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
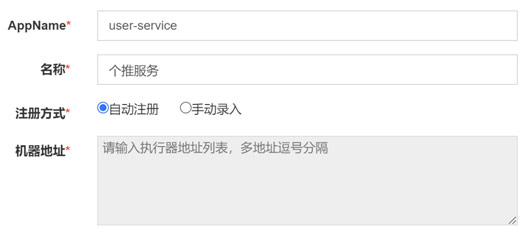
} 在xxl-job中新增執行器
注冊方式選自動注冊,這樣方便動態擴容
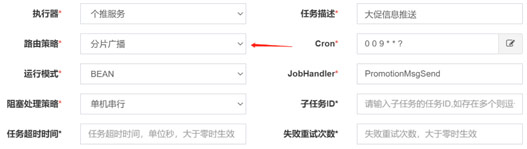
創建任務
路由策略選擇分片廣播
代碼部分
在任務代碼獲取推送用戶時,根據當前的分片及分片總數對用戶ID取余,這樣我們就可以在每個分片節點,獲取不一樣的數據。id值越連續,分片則越均勻。
ShardingUtil.ShardingVO shardingVo = ShardingUtil.getShardingVo(); int numbers = shardingVo.getTotal(); //分片總數 int index = shardingVo.getIndex(); //當前分片索引
假設分片總數為3,當前節點獲取到的分片索引為0,那么查詢推送用戶SQL如下:
SELECT user_id FROM `user_info` WHERE MOD(user_id,3)=0
注意:我們在實際代碼中,分片總數和當前分片索引是以參數的形式傳給查詢的SQL語句的。
如上,即可完成分布式任務。
總結
在某些定時任務需要處理大量數據的情況下,我們可以通過引入分布式任務框架xxl-job,充分利用機器資源,將需要處理的數據均勻的分配到不同的機器上去執行,提高任務執行效率。
















 JavaEE
JavaEE 鴻蒙應用開發
鴻蒙應用開發 集成電路應用開發
集成電路應用開發 人工智能開發
人工智能開發 AI+Linux云計算運維
AI+Linux云計算運維 Python+大數據開發
Python+大數據開發 AI+設計
AI+設計 軟件測試
軟件測試 新媒體+短視頻
新媒體+短視頻 HTML&JS+前端
HTML&JS+前端
















.jpg)