更新時間:2019-09-18 來源:黑馬程序員 瀏覽量:
在2003年之前,谷歌內部還沒有一個成熟的處理框架來處理大規模數據。當時,谷歌的搜索業務迫使工程師們面對處理大規模數據的應用場景,比如計算網站url訪問量和計算網頁倒排索引等等。
那該怎么辦呢?這個答案既簡單又復雜:自己寫一個。
沒錯,當時的工程師需要編寫一個定制的邏輯處理架構來處理數據。由于需要處理的數據量非常大,業務邏輯不太可能只在一臺機器上運行。在許多情況下,我們必須在分布式環境中部署業務邏輯。因此,這種定制的邏輯處理架構還必須包括容錯系統的設計。隨著時間的推移,一組邏輯處理架構將在谷歌內部的不同組之間開發。由于工程師遇到的許多問題是相似的,因此開發的邏輯處理體系結構往往是相似的,但在數據處理方面存在一些邏輯上的差異。毫無疑問,這已經成為一種大家一起重新創造輪子的局面。
這時候,就有工程師想到,能不能改善這一種狀況。MapReduce的架構思想也就由此應運而生。其實MapReduce的架構思想可以從兩個方面來看。一方面,它希望能提供一套簡潔的API來表達工程師數據處理的邏輯。另一方面,要在這一套API底層嵌套一套擴展性很強的容錯系統,使得工程師能夠將心思放在邏輯處理上,而不用過于分心去設計分布式的容錯系統。這個架構思想的結果你早就已經知道了。MapReduce這一套系統在Google獲得了巨大成功。在2004年的時候,Google發布的一篇名為“MapReduce:
Simplified Data Processing on Large Clusters”的論文就是這份成果的總結。
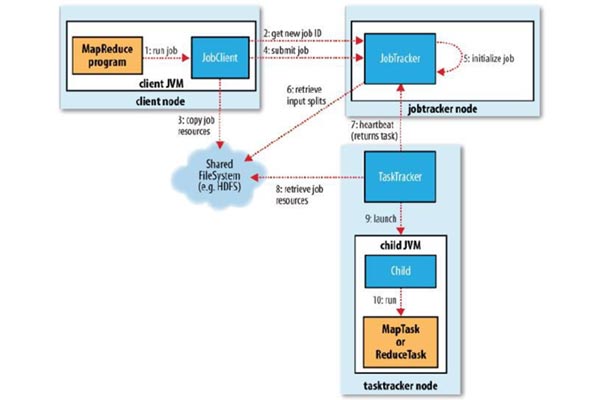
在MapReduce的計算模型里,它將數據的處理抽象成了以下這樣的計算步驟Map:計算模型從輸入源(Input
Source)中讀取數據集合,這些數據在經過了用戶所寫的邏輯后生成出一個臨時的鍵值對數據集(Key/Value
Set)。MapReduce計算模型會將擁有相同鍵(Key)的數據集集中起來然后發送到下一階段。這一步也被稱為Shuffle階段。
很多人都說,這篇MapReduce論文是具有劃時代意義的。可你知道為什么都這么說嗎?這是因為Map和Reduce這兩種抽象其實可以適用于非常多的應用場景,而MapReduce論文里面所闡述的容錯系統,可以讓我們所寫出來的數據處理邏輯在分布式環境下有著很好的可擴展性(Scalability)。
MapReduce在內部的成功使得越來越多的工程師希望使用MapReduce來解決自己項目的難題。但是,就如我在模塊一中所說的那樣,使用MapReduce來解決一個工程難題往往會涉及到非常多的步驟,而每次使用MapReduce的時候我們都需要在分布式環境中啟動機器來完成Map和Reduce步驟,以及啟動Master機器來協調這兩個步驟的中間結果(Intermediate Result),消耗不少硬件上的資源。這樣就給工程師們帶來了以下一些疑問:問題既然已經提出來了,Google的工程師們便開始考慮是否能夠解決上述這些問題。最好能夠讓工程師(無論是新手工程師亦或是經驗老到的工程師)都能專注于數據邏輯上的處理,而不用花更多時間在測試調優上。FlumeJava就是在這樣的背景下誕生的。
這里,我先將FlumeJava的成果告訴你。因為FlumeJava的思想又在Google內容獲得了巨大成功,Google也希望將這個思想分享給業界。所以在2010年的時候,Google公開了FlumeJava架構思想的論文。FlumeJava的思想是將所有的數據都抽象成名為PCollection的數據結構,無論是從內存中讀取的數據,還是Reduce:接收從Shuffle階段發送過來的數據集,在經過了用戶所寫的邏輯后生成出零個或多個結果。我們的項目數據規模是否真的需要運用MapReduce來解決呢?是否可以在一臺機器上的內存中解決呢?我們所寫的MapReduce項目是否已經是最優的呢?因為每一個Map和Reduce步驟這些中間結果都需要寫在磁盤上,會十分耗時。是否有些步驟可以省略或者合并呢?我們是否需要讓工程師投入時間去手動調試這些MapReduce項目的性能呢?
在分布式環境下所讀取的文件。這樣的抽象對于測試代碼中的邏輯是十分有好處的。要知道,想測試MapReduce的話,你可能需要讀取測試數據集,然后在分布式環境下運行,來測試代碼邏輯。但如果你有了PCollection這一層抽象的話,你的測試代碼可以在內存中讀取數據然后跑測試文件,也就是同樣的邏輯既可以在分布式環境下運行也可以在單機內存中運行。
而FlumeJava在MapReduce框架中Map和Reduce思想上,抽象出4個了原始操作(Primitive Operation),分別是parallelDo、groupByKey、 combineValues和flatten,讓工程師可以利用這4種原始操作來表達任意Map或者Reduce的邏輯。同時,FlumeJava的架構運用了一種Deferred Evaluation的技術,來優化我們所寫的代碼。對于Deferred Evaluation,你可以理解為FlumeJava框架會首先會將我們所寫的邏輯代碼靜態遍歷一次,然后構造出一個執行計劃的有向無環圖。這在FlumeJava框架里被稱為Execution Plan Dataflow Graph。有了這個圖之后,FlumeJava框架就會自動幫我們優化代碼。例如,合并一些本來可以通過一個Map和Reduce來表達,卻被新手工程師分成多個Map和Reduce的代碼。
FlumeJava框架還可以通過我們的輸入數據集規模,來預測輸出結果的規模,從而自行決定代碼是放在內存中跑還是在分布式環境中跑。
總的來說,FlumeJava是非常成功的。但是,FlumeJava也有一個弊端,那就是FlumeJava基本上只支持批處理(Batch Execution)的任務,對于無邊界數據(Unbounded Data)是不支持的。所以,Google內部有著另外一個被稱為Millwheel的項目來支持處理無邊界數據,也就是流處理框架。
在2013年的時候,Google也公開了Millwheel思想的論文。這時Google的工程師們回過頭看,感嘆了一下成果,并覺得自己可以再優秀一些:既然我們已經創造出好幾個優秀的大規模數據處理框架了,那我們能不能集合這幾個框架的優點,推出一個統一的框架呢?這也成為了Dataflow Model誕生的契機。
在2015年時候,Google公布了Dataflow Model的論文,同時也推出了基于Dataflow Model思想的平臺Cloud Dataflow,讓Google以外的工程師們也能夠利用這些SDK來編寫大規模數據處理的邏輯。講到這么多,你可能會有個疑問了,怎么Apache Beam還沒有出場呢?別著急,Apache Beam的登場契機馬上就到了。
前面我說了,Google基于Dataflow Model的思想推出了Cloud Dataflow云平臺,但那畢竟也需要工程師在Google的云平臺上面運行程序才可以。如果有的工程師希望在別的平臺上面跑該如何解決呢?
所以,為了解決這個問題,Google在2016年的時候聯合了Talend、Data Artisans、Cloudera這些大數據公司,基于Dataflow Model的思想開發出了一套SDK,并貢獻給了Apache Software Foundation。而它Apache Beam的名字是怎么來的呢?Beam的含義就是統一了批處理和流處理的一個框架。
這就是Apache Beam的發展歷史,從中你可以看到它擁有很多優點,而這也是我們需要Beam的原因。
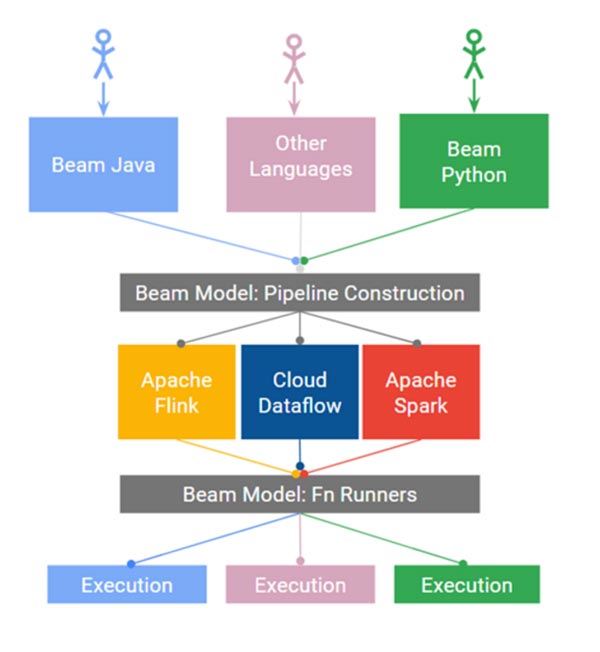
在現實世界中,很多時候我們不可避免地需要對數據同時進行批處理和流處理。Beam提供了一套統一的API來處理這兩種數據處理模式,讓我們只需要將注意力專注于在數據處理的算法上,而不用再花時間去對兩種數據處理模式上的差異進行維護。它能夠將工程師寫好的算法邏輯很好地與底層的運行環境分隔開。也就是說,當我們通過Beam提供的API寫好數據處理邏輯后,這個邏輯可以不作任何修改,直接放到任何支持Beam API的底層系統上運行。關于怎么理解這個優點,其實我們可以借鑒一下SQL(Structure Query Language)的運行模式。
我們在學習SQL語言的時候,基本上都是獨立于底層數據庫系統來學習的。而在我們寫完一個分析數據的Query之后,只要底層數據庫的Schema不變,這個Query是可以放在任何數據庫系統上運行的,例如放在MySql上或者Oracle DB上。
同樣的,我們用Beam API寫好的數據處理邏輯無需改變,可以根據自身的需求,將邏輯放在Google
CloudDataflow上跑,也可以放在Apache Flink上跑。在Beam上,這些底層運行的系統被稱為Runner。現階段Apache
Beam支持的Runner有近十種,包括了我們很熟悉的Apache Spark和Apache Flink。
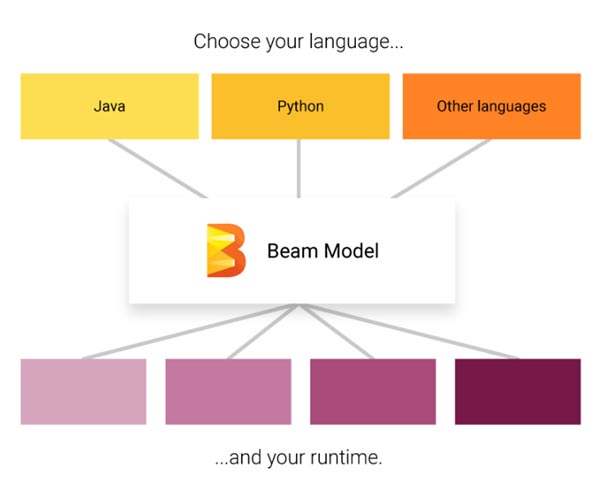
當然,最后Apache
Beam也希望自己編寫的sdk能夠支持任意數量的語言。在這個階段,Beam持Java、Python和Golang。換句話說,通過apache
beam,我們最終可以使用我們自己的編程語言,通過一組beam模型統一的數據處理api,編寫適合您的應用程序場景的數據處理邏輯,并在您喜歡的運行程序上運行它。
推薦了解:
大數據培訓課程
















 JavaEE
JavaEE 鴻蒙應用開發
鴻蒙應用開發 集成電路應用開發
集成電路應用開發 人工智能開發
人工智能開發 AI+Linux云計算運維
AI+Linux云計算運維 Python+大數據開發
Python+大數據開發 AI+設計
AI+設計 軟件測試
軟件測試 新媒體+短視頻
新媒體+短視頻 HTML&JS+前端
HTML&JS+前端
















.jpg)